Generating Fast GPU Kernels without Programming in CUDA/Triton
As GPUs grow more sophisticated, achieving optimal performance for modern AI applications such as LLMs and various GenAI tasks depends crucially on developing fast GPU kernels. This task is currently handled by specialized GPU experts.
Writing high-performance GPU kernels in NVIDIA CUDA or AMD ROCm requires deep knowledge of GPU architecture and significant engineering time. Modern ML compilers like TVM, Triton, and Mojo alleviate some of these challenges by providing higher-level programming interfaces, typically in Python. However, these tools still require developers to manually manage aspects such as workload distribution across thread blocks, computation organization within these blocks, and synchronization and communication. As a result, implementing an efficient attention kernel could entail writing approximately 700 lines of Python code using Triton, or as much as 7,000 lines of C++ code in CUDA.

Can we get fast GPU kernels without programming in CUDA/Triton? Motivated by this question, our team at Carnegie Mellon University has created Mirage, a tool that automatically generates fast GPU kernels for PyTorch applications through superoptimization techniques. For example, to get fast GPU kernels for attention, users simply need to write a few lines of Python code to specify the computation of attention.
# Use Mirage to generate GPU kernels for attention
import mirage as mi
graph = mi.new_kernel_graph()
Q = graph.new_input(dims=(64, 1, 128), dtype=mi.float16)
K = graph.new_input(dims=(64, 128, 4096), dtype=mi.float16)
V = graph.new_input(dims=(64, 4096, 128), dtype=mi.float16)
A = graph.matmul(Q, K)
S = graph.softmax(A)
O = graph.matmul(S, V)
optimized_graph = graph.superoptimize()Mirage automatically searches for possible GPU kernels for attention. The search space includes existing manually designed attention kernels (e.g., FlashAttention and FlashDecoding) as special cases. It also includes other implementations that outperform today’s handwritten ones by up to 3.5x for certain use cases. The GPU kernels generated by Mirage can directly operate on PyTorch tensors and be called in your PyTorch program.
import torch
input_tensors = [
torch.randn(64, 1, 128, dtype=torch.float16, device='cuda:0'),
torch.randn(64, 128, 4096, dtype=torch.float16, device='cuda:0'),
torch.randn(64, 4096, 128, dtype=torch.float16, device='cuda:0')
]
# Call the Mirage-generated kernel to perform attention on PyTorch tensors
output = optimized_graph(input_tensors)Why Mirage?
Compared to traditional CUDA/Triton programming, Mirage represents a significant paradigm shift and offers three major advantages:
Higher productivity: Programming modern GPUs requires substantial engineering expertise due to the increasingly heterogeneous GPU architectures. Mirage aims to boost the productivity of MLSys engineers by simplifying this process. Engineers need only specify their desired computation at the PyTorch level; Mirage then takes over, automatically generating high-performance GPU kernels tailored to various GPU architectures. This automation frees programmers from the burdensome task of writing low-level, architecture-specific code.
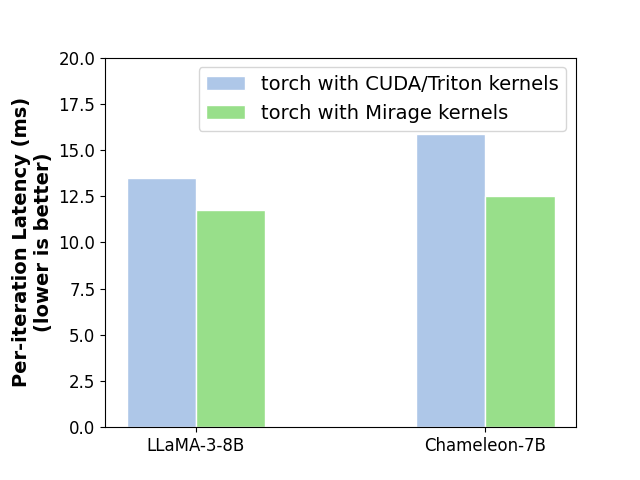
Better performance: Manually written GPU kernels often fail to achieve optimal performance as they may overlook subtle yet crucial optimizations that are challenging to identify manually (see examples in Part 2). Mirage automates the exploration of possible GPU kernels for any given PyTorch program, examining a broad range of implementations to uncover the fastest ones. Our evaluations across various LLM and GenAI benchmarks show that the kernels generated by Mirage are generally 1.2–2.5 times faster than the best human-written or compiler-generated alternatives. Furthermore, integrating Mirage kernels into PyTorch programs reduces overall latency by 15–20%, with only a few lines of code changes required.
Stronger correctness. Manually implemented GPU kernels in CUDA/Triton are error-prone, and bugs in GPU kernels are hard to debug and locate. Instead, Mirage leverages formal verification techniques to automatically verify the correctness of the generated GPU kernels.
The remaining of this blog introduces the Mirage project in more detail. Part 1 covers the basics of the GPU architecture and introduces Mirage’s uGraphs that describe computation at multiple levels of the GPU hierarchy. Part 2 uses several case studies to show why Mirage generates faster GPU kernels than the human-written or compiler-generated alternatives.
Part 1. GPU Architecture & Mirage’s uGraph
Computations on GPUs are structured around kernels, which are functions running simultaneously across multiple streaming multiprocessors (SM) in a single-program-multiple data (SPMD) fashion. A GPU kernel organizes its computation using a grid structure comprised of thread blocks, with each thread block running on a single SM. Each block further includes multiple threads to perform computation on individual data elements.
GPUs also have sophisticated memory hierarchy to support this complex processing structure. Each thread has its own register file (RF) for quick data access. All threads within a thread block share access to a common shared memory, which facilitates efficient data exchange and collective operations among them. Finally, all threads within a kernel can access large device memory allocated to the entire GPU.
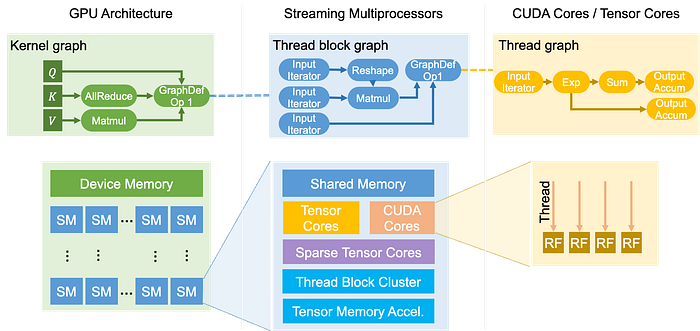
Mirage uses a uGraph to represent a kernel’s execution on GPUs. A uGraph contains hierarchical graphs at multiple levels, designed to represent computation at the kernel, thread block, and thread levels. Essentially, a kernel graph encapsulates the computation over the entire GPU, a thread block graph handles computation on an individual streaming multiprocessor (SM), and a thread graph addresses computation at the CUDA or tensor core level. For those interested in the details of how a uGraph functions and its benefits for GPU programming, further insights are available in a dedicated blog post.
How Mirage Generates GPU Kernels?
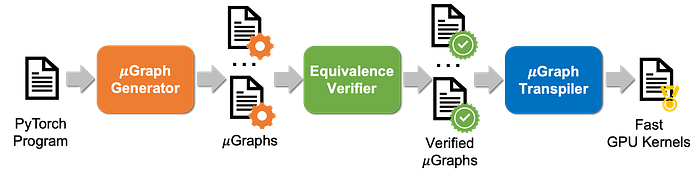
The diagram highlights Mirage’s workflow. Starting with an input PyTorch program, Mirage’s uGraph generator automatically searches for possible uGraphs that match the functionality of the input. The search captures a range of GPU optimizations at the kernel, thread block, and thread levels. Each candidate uGraph generated during this process is forwarded to the equivalence verifier, which checks whether the uGraph is equivalent to the input. Next, the uGraph transpiler converts all verified uGraphs into CUDA kernels. Finally Mirage identifies and returns the best CUDA kernel.
Part 2. Why Mirage Generates Faster Kernels?
Our tests across various LLM and GenAI benchmarks show that the kernels generated by Mirage are generally 1.2–2.5 times faster than existing hand-written or compiler-generated kernels. We focus on the Transformer architecture prevalent in modern LLMs as an example to identify several GPU optimizations that are missing in current ML systems. We organize these optimizations into four categories.

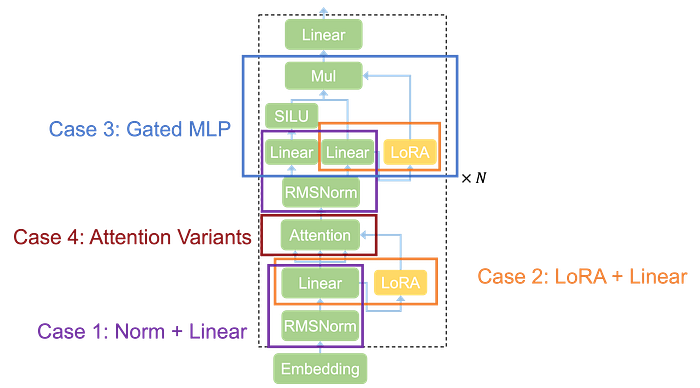
Case 1: Normalization + Linear
Normalization techniques, such as LayerNorm, RMSNorm, GroupNorm, and BatchNorm, are widely used in LLMs. Today’s ML compilers typically treat these normalization layers as separate entities and run them in independent kernels. This separation is mainly because normalization layers require both reduction and broadcast operations, which complicates fusion with other computations. However, Mirage discovers that many of these normalization layers can be fused with subsequent linear layers, such as matrix multiplications, by performing proper algebraic transformations.
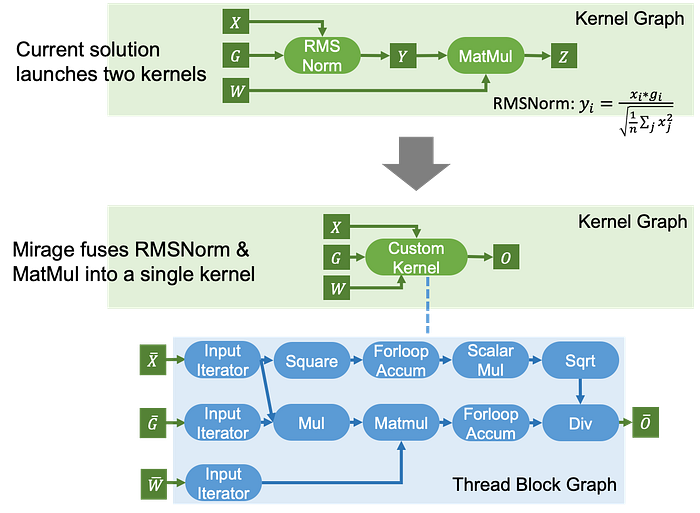
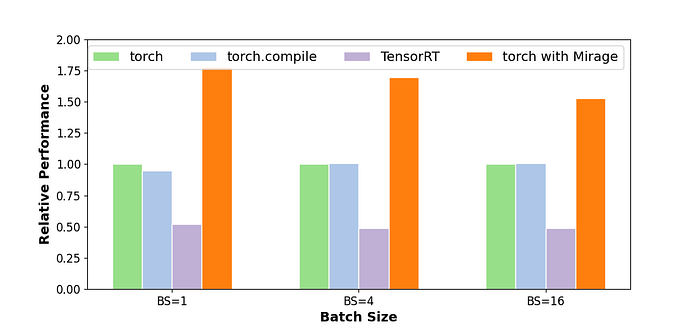
The custom kernel generated by Mirage leverages the commutativity of division in RMSNorm and multiplication in MatMul, moving division after MatMul. This rearrangement preserves functional equivalence while eliminating the need to create the intermediate tensor Y in device memory. This kernel is 1.5–1.7x faster than running the two operators separately.
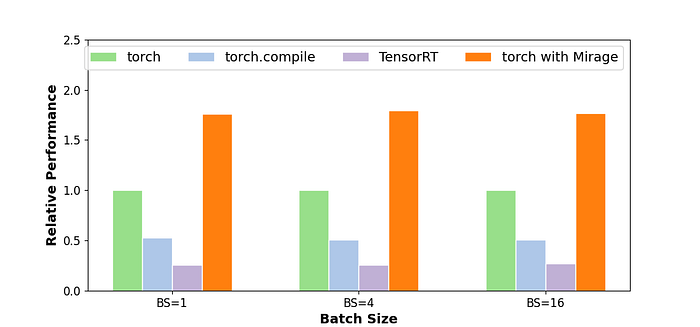
Case 2: LoRA + Linear
Low-rank adaption (LoRA) has been widely used to adapt a pre-trained model to specialized domains and tasks. These LoRA adapters are generally integrated into the linear layers of a model, introducing additional small matrix multiplications. Existing ML systems generally launch separate kernels for the original MatMul and the two MatMuls in LoRA, introducing high kernel launch overheads since the LoRA operators involve very low computational costs.

Mirage discovers a kernel that fuses the three MatMuls and the subsequent addition into a single kernel. The new kernel reorganizes the computation into two thread block level MatMuls by leveraging the following algebraic transformation: W x X + B x A x X = (W | B) x (X | (A x X)). The two concatenations ( | ) involve no actual computation and are handled by updating tensor offsets within the GPU shared memory. The kernel discovered by Mirage is 1.6x faster than the kernels used in existing systems.
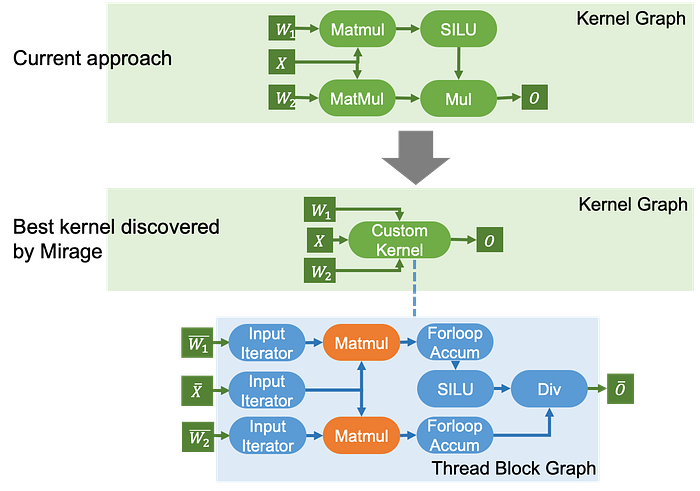
Case 3: Gated MLP
Gated MLP layers are currently used in many LLMs such as LLAMA-2, LLAMA-3, and their variants. In these layers, the input tensor X is multiplied with two weight matrices, and the outputs are then combined to produce the final result. Mirage discovers a kernel that performs the two MatMuls, a SiLU activation, and a following element-wise multiplication, reducing both kernel launch overhead and access to device memory.
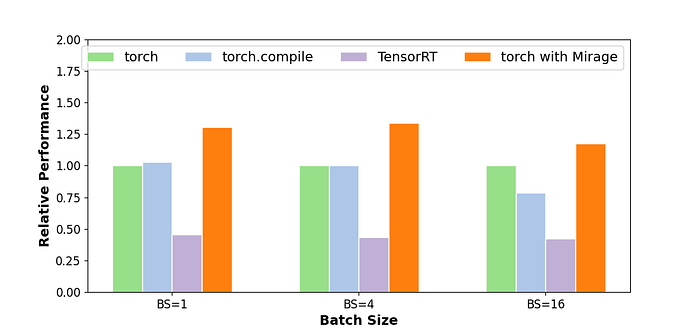
Case 4: Attention Variants
Most of today’s LLMs utilize attention mechanisms and their variants. While there are already highly optimized implementations for attention, such as FlashAttention, FlashInfer, and FlexAttention, supporting different variants of attention often necessitates the creation of new custom kernels. In this blog post, we will explore two such variants to showcase how Mirage effectively discovers custom GPU kernels tailored for specialized attention computations.
Case 4.1: Attention with Query-Key Normalization
The standard LLaMA architecture often exhibits complex divergence due to slow norm growth during training. To address this issue, several recent architectures, including Chameleon, ViT-22B, and Google’s recent paper, have introduced query-key normalization (QK-Norm) into the LLaMA architecture. QK-Norm applies layer normalization to the query and key vectors before attention (i.e., the two LayerNorm operators before Attention in PyTorch’s kernel graph before). These additional normalization layers are not yet supported by existing attention implementations and require separate kernel launches in existing systems.
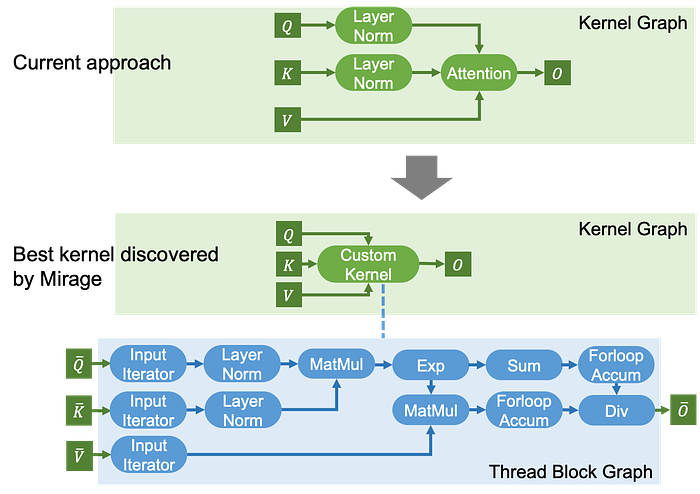
For attention variants that involve additional computations before and/or after attention, integrating these computations into the attention kernel can significantly enhance GPU performance. This integration, however, necessitates the development of custom kernels. For attention augmented with QK-Norm, Mirage automatically generates a new kernel that fuse these computations together, which prevents creating intermediate results in the GPU device memory. In addition, this custom kernel also performs existing GPU optimizations tailored for attention, resulting in 1.7–2.5x performance improvement.
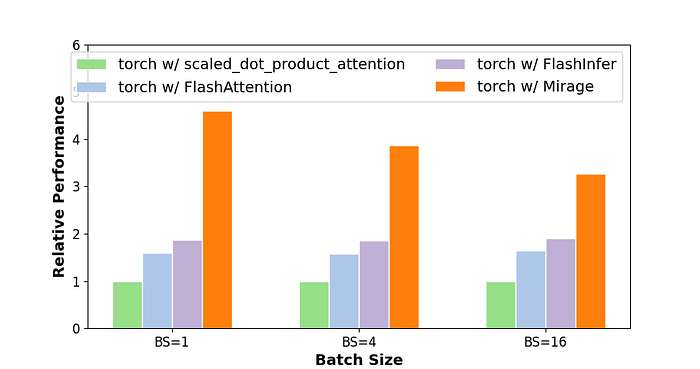
Case 4.2: Multi-Head Latent Attention
Another commonly used attention variant is multi-head latent attention (MLA), which optimizes memory usage by compressing the traditional key-value cache of attention into a more compact latent vector. This change introduces two linear layers before attention, as shown in the figure below. However, similar to the situation with query-key normalization, these additional linear layers are not yet supported by the standard attention kernels used today. Consequently, they require separate kernel launches in existing systems.
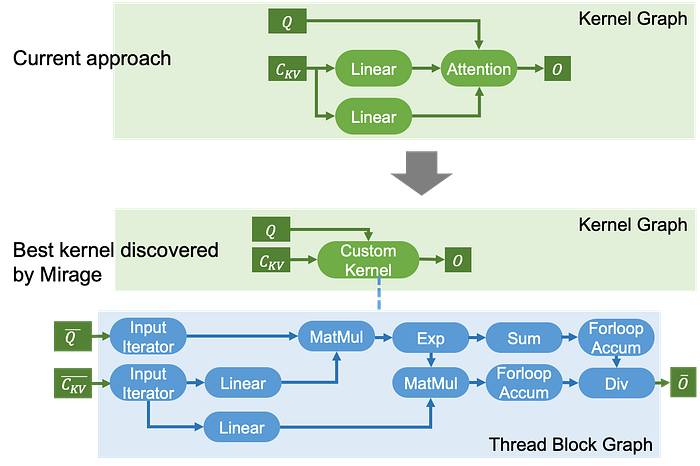
Similar to the approach taken with query-key normalization, Mirage generates a custom kernel that integrates the linear layers with the attention mechanism into a single kernel. This fusion prevents storing intermediate key-value vectors in the GPU device memory.
Long-Term Vision
Mirage’s long-term goal is to promote a future scenario where ML engineers can implement ML models on modern GPUs by only specifying the mathematical operations. By leveraging superoptimization techniques of Mirage, these specifications can be translated into highly optimized GPU implementations automatically. This capability is becoming increasingly crucial as LLMs and other generative AI methodologies progress at an unprecedented rate, and deploying these techniques across diverse real-world applications necessitates performant and efficient GPU support.
Mirage project members: Mengdi Wu, Xinhao Cheng, Shengyu Liu, Chunan Shi, Jianan Ji, Oded Padon, Xupeng Miao, Zhihao Jia
Mirage software: https://github.com/mirage-project/mirage
